
PDFからコピペすると日本語の途中に余計な半角スペースが入る
仕事の書類をPDFでもらうとコピペでテキストに変換することが多いです。
テキストにすると必要な部分だけに内容を整理したり、見やすい大きな文字で表示できるのでとても便利です。
PDFのテキスト化としては、PDFをGoogleドライブにアップロードしてGoogleドキュメントとして開くという方法もあります。
まずPDFをGoogleドライブにアップロードします。
次にブラウザでGoogleドライブのファイルリストを表示
右クリックで「アプリで開く」>「Googleドキュメント」で編集可能なドキュメントに変換してくれます。
PDFの設定でコピペや変換が禁止されているドキュメントはOCRでテキストに変換します。
ただ、おそらくWordから作ったPDFだと思うのですが、半角英数字と日本語の間に不要なスペースが挿入されることが結構あります。
日本語中の英単語を読みやすくするための工夫なのかもしれませんが。テキスト変換するとこのスペースが邪魔なんですよね。実害はそれほどないのですが、なんとも気持ち悪い。
Webアプリでコピペで変換
そんなわけでプログラムを書いて不要なスペースを自動除去できるようにしました。
こういうのはSEDとか使ってコマンドラインでやったりするのかもしれませんが、わたしはGUI派なのと、変換の様子が確認できるようにしたいと思ってWebアプリにしました。
ついでに全角半角変換とか、自分のニーズに合わせていろいろな変換機能もつけました。
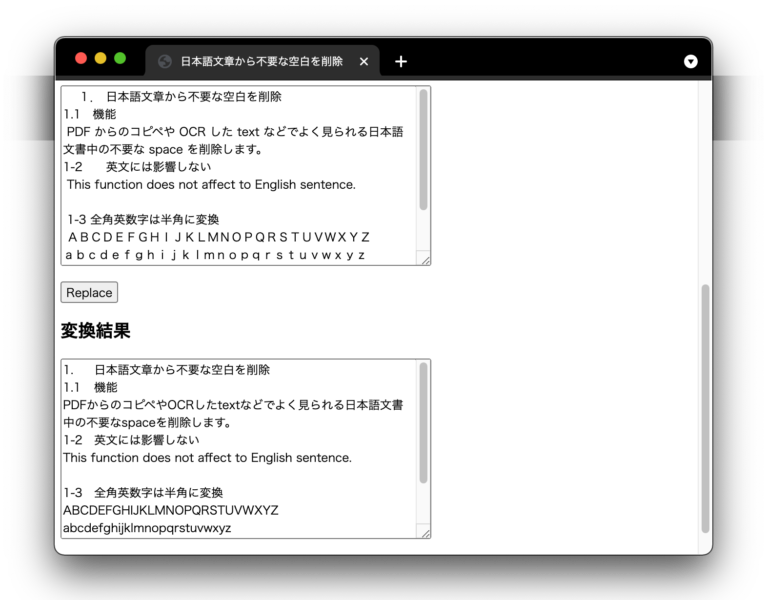
アプリ:日本語文書から不要な空白を削除-github pages
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>日本語文章から不要な空白を削除</title>
<style>
html {
font-family: sans-serif;
font-size: 100%;
}
textarea,
button {
font-family: inherit;
font-size: 100%;
}
</style>
</head>
<body>
<H1>日本語文章から不要な空白を削除</H1>
<p>
PDFからのコピペやOCRしたテキストなどでよく見られる <br>
日本語文書中の不要な空白を削除します。<br>
例:「この Apple は」→「このAppleは」<br>
例:「図 1 に示す」「図1に示す」など
</p>
<p> 英文中の空白は無視します。<br>
「1.1 はじめに」のような章番号の後ろの空白も無視します。
</p>
<p>
全角英数字は半角に変換します。
ついでに行頭の空白を削除、「,」を「、」に変換します。
</p>
<p>
取り切れない部分もあります。<br>
やっていることは単純な置換の繰り返しなので、<br>
ご自分の変換したい文章に合わせて改造して下さい
</p>
<hr>
<h2>元のテキストをペースト</h2>
<p><button id="clear">Clear Sample Text</button></p>
<textarea name="" id="text_original" cols="60" rows="10">
1. 日本語文章から不要な空白を削除
1.1 機能
PDF からのコピペや OCR した text などでよく見られる日本語文書中の不要な space を削除します。
1-2 英文には影響しない
This function does not affect to English sentence.
1-3 全角英数字は半角に変換
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
0123456789
</textarea><br>
<p>
<button id="replace">Replace</button>
</p>
<h2>変換結果</h2>
<textarea name="" id="text_result" cols="60" rows="10"></textarea><br>
<p>
<button id="copy">Copy to Clipboard</button>
</p>
<script>
window.onload = function () {
document.getElementById("replace").addEventListener("click", function () {
let result = document.getElementById("text_original").value;
result = result.replace(/^[ ]+/gm, ''); //行頭のスペース削除
result = result.replace(/[A-Za-z0-9]/g, function (s) {
return String.fromCharCode(s.charCodeAt(0) - 0xFEE0);
}); //全角英数字を半角に
result = result.replace(/([.])/g, '.');//全角ピリオドを半角に
result = result.replace(/,/g, '、');//コンマを句点に
result = result.replace(/^([0-9\.\-]{2,})[ ]+/gm, '$1\t');//章・節番号の後ろにタブを付ける
// mオプション:行頭(^)や行末($)が各行の行頭・行末にもマッチする
result = result.replace(/ +([亜-熙ぁ-んァ-ヶ])/g, '$1');//全角文字の前のスペースを除去
result = result.replace(/([亜-熙ぁ-んァ-ヶ]) +/g, '$1');//全角文字の後ろのスペースを除去
//他の変換も行いたい場合には適宜 result=result.replace() を追加する
document.getElementById("text_result").value = result;
}, false);
document.getElementById("clear").addEventListener("click", function () {
document.getElementById("text_original").value = "";
}, false);
document.getElementById("copy").addEventListener("click", function () {
const textarea = document.getElementById("text_result");
textarea.select();
document.execCommand("copy");
}, false);
};
</script>
</body>
</html>
備忘録:各変換の正規表現
やっていることはとてもシンプルで、textareaに入っているテキストデータをjavascriptのreplaceメソッドを使って変換しているだけです。
変換処理はreplaceボタンのclickイベントに設定した無名関数の中にあります。
正規表現の備忘録として変換の内容をメモっておきます。
result = result.replace()を必要な変換の数だけ繰り返します。
行頭のスペース削除
javascript
let result = text_originnal.replace(/^[ ]+/gm, '');
// [ ]の中身は半角スペースと全角スペース
Javascriptの行頭・行末マッチにはmオプションが必須
作っている時に結構ハマったのがjavascriptにおける行頭マッチです。
最初はデータ全体に繰り返し適用ということで" /g "オプションだけつけていました。
たぶんSEDとかならこれで動くと思うのですが、Javascriptだと文章の冒頭の見出しにしかマッチしません。
散々悩んでやっと分かったのが"m"オプションの存在でした。
Javascriptの正規表現では"^"は行頭ではなく文字列の先頭を表します。なので改行の有無に関係なくstringの最初しかマッチしません。
mオプションを付けることで、"^"が行頭を意味するようになります。
通常はgオプション(繰り返しマッチ)と併用することになるでしょう。
"$"も同様です。通常は文字列の最後ですがmオプションを付けることで行末にマッチします。
これってなんか昔も同じ事で悩んだような気がするんですよねぇ。正規表現もたまにしか使わないから忘れてしまう。
全角英数字を半角に
javascript
result = result.replace(/[A-Za-z0-9]/g, function (s) {
return String.fromCharCode(s.charCodeAt(0) - 0xFEE0);
});
どこかからコピペしてきたコードです。全角英数字のコードから0xFEE0を引くと半角になるらしいです。
replaceの第二引数に無名関数を渡すのとか格好いいなぁと思います。
全角英数字は扱いづらいので使用禁止にして欲しいなぁとも思います。
全角ピリオドを半角に、コンマを句点に
javascript
result = result.replace(/([.])/g, '.');
result = result.replace(/,/g, '、');
単純な置換です。
まとめちゃってもいいんですけど、必要に応じて追加していったので別々になっています。
章・節番号の後ろにタブを付ける
javascript
result = result.replace(/^([0-9\.\-]{2,})[ ]+/gm, '$1\t');
私がよく受け取る文書には"1-1"とか"1-2-3"といった形式で章・節番号が振られています。
このまま変換すると番号と見出しの間のスペースが除去されてしまうのでタブに置き換えます。タブの方が位置合わせもしやすいですし。
見出しの判定は“行頭に数字とハイフンが2文字以上続き、その後ろに半角or全角スペースがある”という条件です。
見出し以外のものが引っかかる可能性はありますが、それくらいの変換ミスは手直しでも良いでしょう。
全角文字の前後のスペースを削除
javascript
result = result.replace(/ +([亜-熙ぁ-んァ-ヶ])/g, '$1');//全角文字の前のスペースを除去
result = result.replace(/([亜-熙ぁ-んァ-ヶ]) +/g, '$1');//全角文字の後ろのスペースを除去
英単語同士の間隔は残したいので、日本語文字(半角英数以外の文字)にくっついているスペースを除去します。
コードでは"+"記号の前に半角スペースが入っています。
調べてみると、日本語にマッチする正規表現は以外と面倒で、よく使われるものとしては
[亜-熙ぁ-んァ-ヶ]
というのが見つかりましたので、それを使っています。
半角英数字以外の文字と捉えて
[^0-9a-zA-Z]
という正規表現もあります。この場合は英語以外の外国語も扱う場合には使えません。
クリップポードにコピーするボタンを設置
javascript
document.getElementById("copy").addEventListener("click", function () { const textarea = document.getElementById("text_result"); textarea.select(); document.execCommand("copy"); }, false);
これもどこかからのコピペです。
ちなみにペーストはセキュリティ上NGなブラウザが多いらしいです。