
Pythonでのスクレイピングはやってみたら楽だった
スクレイピングとはWebサイトから欲しいデータだけを抜き出すことです。
以前、Javascriptでスクレイピングっぽいことをやったことがあります。
そのときはHTMLを読み込んだString変数に対して正規表現を使った処理を書きまくりました。
ライブラリを使わなかったこともあり、とにかく面倒でした。
最近、Pythonの勉強を始めたのでスクレイピングをやってみたら、すごく楽だったのでやりかたを記録しておきます。
ただ、スクレイピングは使い方を誤ると、相手のサーバーに大きな負荷をかけたり、知的所有権を侵害する恐れがありますので、節度を持って使います。
Selenium、ChromeDriverをインストール
Pythonでスクレイピングが楽なのはライブラリとツールが揃っているからです。
とりあえず、Selenium、ChromeDriver、BeautifulSoupといったあたりが定番みたいです。
今回はSeleniumとChromeDriverを使ったスクレイピングのメモです。
seleniumはpipでインストールしました。
//ライブラリのインストール
pip install selenium
seleniumはwebdriverという機能を使ってブラウザを制御できるライブラリです。
ブラウザを制御できるので項目入力やボタン操作なんかもできます。
また、いったんHTMLを読み込んだあとでJavascriptを使って動的に生成するページでもスクレイピングできます。
もともとWebサイトのテストなんかに使うライブラリらしいです。
ブラウザを制御するためには各ブラウザに合った機能拡張を組み込む必要があります。そのGoogle Chrome用がchromedriverです。
ウチはMacなのでHomebrewでインストールしました。Windowsの場合はインストールに関してイロイロと細かい手順があるらしいです。
//Google Chromeを制御する機能拡張のインストール(Mac)
brew install chromedriver
Chromedriver起動時のセキュリティ警告
Seleniumから初めてchromedriverを起動するとmacOSのセキュリティ警告がでます。初回インストール時だけでなく、chromedriverをアップグレードした時にも出ました。
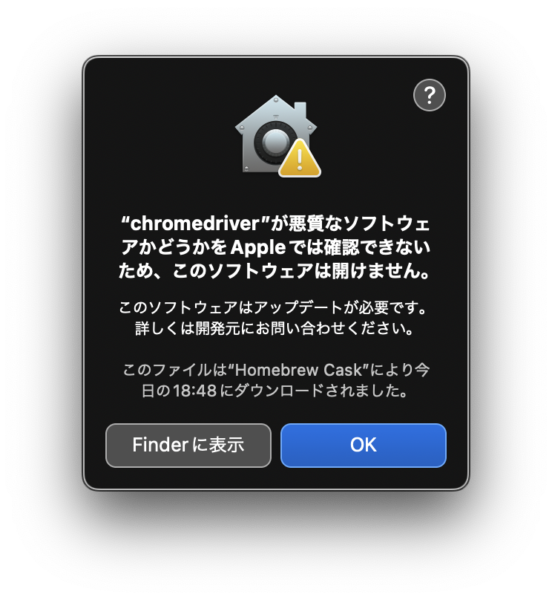
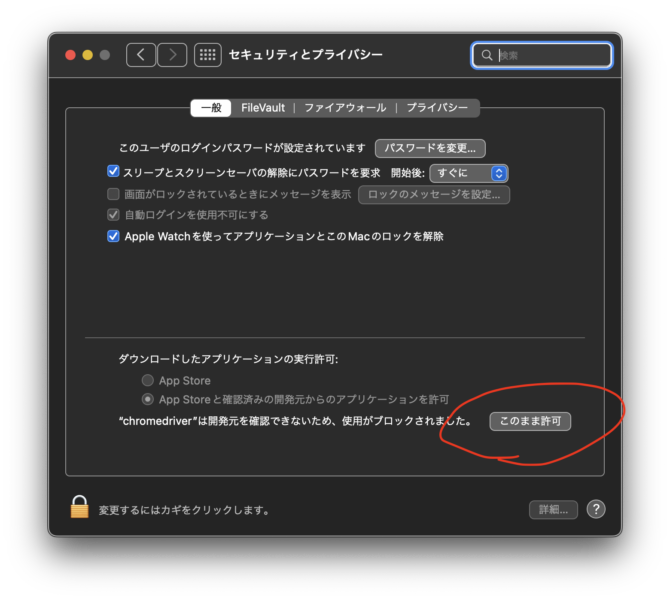
実行するには「システム環境設定」「セキュリティとプライバシー」「一般」で、「このまま許可」ボタンをクリックします。もちろん自己責任です。
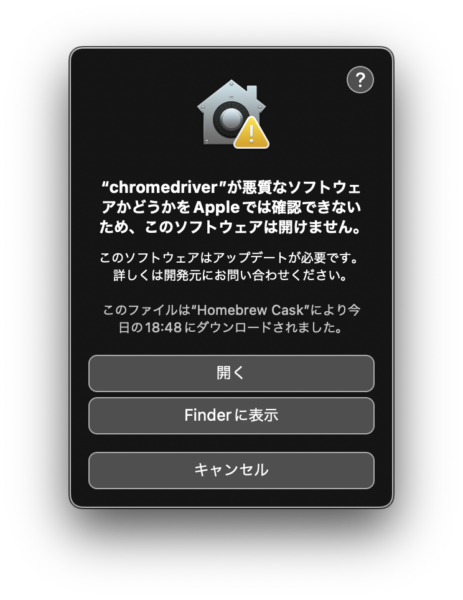
「このまま許可」をした後にも確認がでます。「開く」をクリック。もちろん自己責任です。ひゃー。
ChromeDriverでChromeを起動する
SeleniumとChromeDriverでWebサイトにアクセスするには以下のようにします。
from selenium import webdriver
browser = webdriver.Chrome() #Chromeを起動browser = webdriver.Chrome()を実行したところでwebdriver用のchromeが起動します。
webdriverでコントロールされているページには「自動テストソフトウェアによって制御されています」と表示されます。
ただし、普通に人間が操作することもできます。
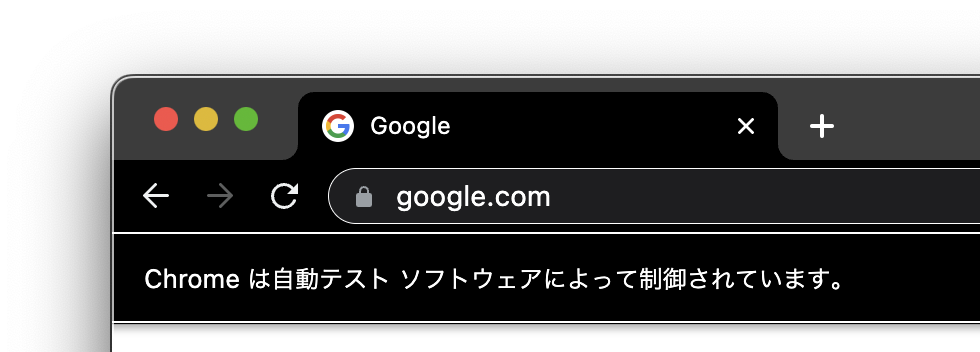
すでにChromeが起動している場合にはもうひとつChromeが起動します。
アプリケーションスイッチャーにも2個表示されます。なんか面白いですね。

ブラウザを表示させたくないときには、以下のようにオプションで--headlessを指定します。もっとも、headlessで使うのはスクレイピングのスクリプトが完成してからでいいでしょう。
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless') #画面表示をしないオプション
browser = webdriver.Chrome(options=options) #Chromeを起動 引数を省略すれば画面が表示される
Webサイトにアクセスする
url = 'https://**************.***' #サイトのURL
browser.get(url) #サイトにアクセスbrowser.get(url)を実行すると、webサイトのデータがbrowserオブジェクトに入ります。
あとは"browser"オブジェクトのプロパティやメソッドでWebサイトのデータを取り出したり、Webページを操作できます。
ちなみに、browserオブジェクトのデータは現在ウインドウの内容に逐次更新されます。
プログラムからコントロールした場合はもちろん、手作業で他の画面に遷移した場合にも更新されます。
ここまでのコードをまとめると以下のようになります。
あとで必要になるByというライブラリも読み込んでいます。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
options = Options()
# options.add_argument('--headless') # 画面表示をしない場合
# browser = webdriver.Chrome(options=options)
browser = webdriver.Chrome() #Chromeを起動 引数を省略すれば画面が表示される
url = 'https://******.***' #スクレイピング対象サイトのURL
browser.get(url) #サイトにアクセス
スクレイピングの試行錯誤にはJupyter Labが便利
Webサイトにアクセスするまで
スクレイピングであれこれ試行錯誤をするときには、Jupyter Labを使うととても便利です。
Jupyter Labはセルに書いたプログラムの実行結果を保持してくれます。
あるセルで上記のbrowser.get(url)までを実行しておけば、webサイトのデータ(browrserオブジェクト)がJupyter Labの内部に保存されています。
とりあえずここで区切り、browserオブジェクトから情報を取り出す処理は別のセルに書くようにします。
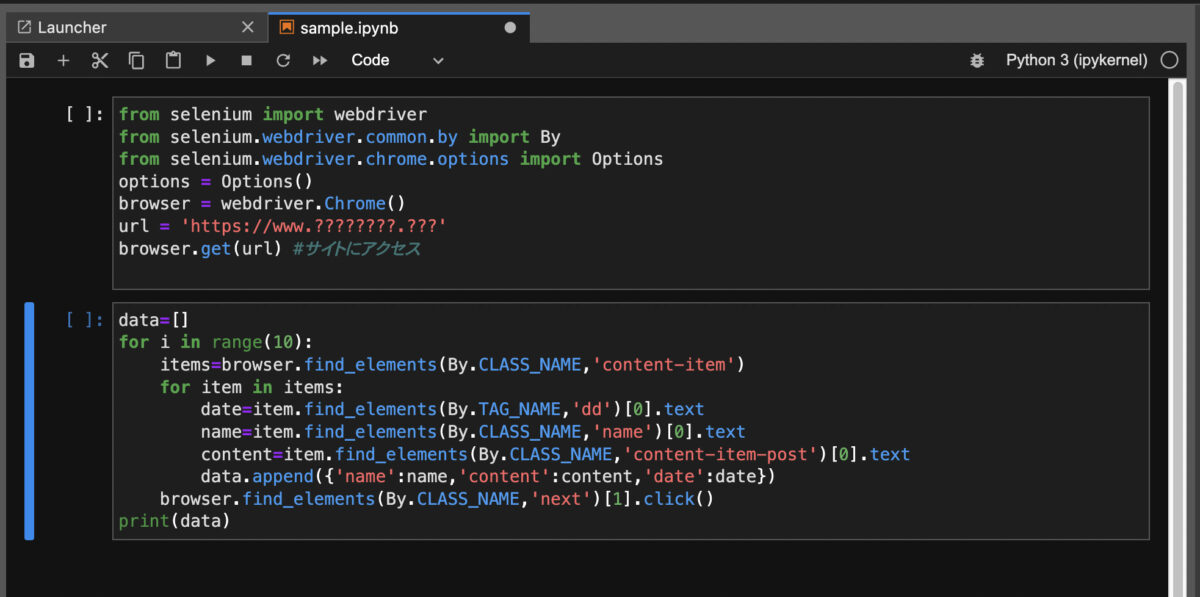
こうすると情報抽出部分を書き換えるたびにwebサイトにアクセスする無駄がありません。情報元のサイトにも余分な負荷をかけずにすみます。
新しい情報を取りたいときにはbrowser.get(url)の書かれたセル内でshift-returnを押して再実行します。
Jupyter Labは細切れにコードを書いて試すことができ、いちいちスクリプトを保存して起動する手間もかからないので、試行錯誤には本当に便利です。
HTMLから要素を見つける find_element, find_elements
browser.get(url)で取得したHTMLから条件に合った要素を探し出すメソッドがbrowser.find_elementとbrowser.find_elementsです。
find_elementは最初に見つかった物だけを返します。
find_elementsは見つかったすべての要素を配列(リスト)として返します。
メソッドを使うためには条件を指定するためのByというライブラリを読み込んでおく必要があります。
from selenium.webdriver.common.by import By ##.find.elementで使う定数を定義例えば"name"というIDを持つ要素を見つけるには次のようにします。
IDやClass名を調べるにはソースコードを見る必要があります。
ChromeでWebページ上で調べたい要素を右クリックして「検証」を選ぶと、ソースコード上の該当する場所が表示されます。
name_element = browser.find_element(By.ID,'name')
find_elements(複数形)の場合はヒットした要素がすべて含まれるリストを返します。
例えば'name'というクラス名を持つ要素を抜き出す場合は以下のようなコードになります。
ひとつだけ取り出す時はインデックスを指定します。
for inで回せばすべてを閲覧できます。
name_elements = browser.find_elements(By.CLASS_NAME,'name')
name_element = browser.find_elements(By.CLASS_NAME,'name')[0] #ひとつだけ。find_elementと同じ結果になる
#すべてを出力
for elem in name_elements:
print(elem.text)
By.に使えるセレクタの種類は以下になります。
By.につける文字
CLASS_NAME :クラス名
CSS_SELECTOR :CSSセレクタ
ID :id属性
LINK_TEXT :リンクが設定されているテキスト
NAME :name属性
PARTIAL_LINK_TEXT :リンクが設定されているテキストの一部
TAG_NAME :タグ名
XPATH :XPATH(HTMLの階層をファイルパスみたいに書く)以前はセレクタごとにメソッドが分かれていた
以前はセレクタごとにメソッドが分かれていました。
例えば クラス名で探すときは、
driver.find_element_by_class_name("className")
といったメソッドを使っていました。
新しいバージョンでは非推奨もしくは使えなくなっているみたいです。
今でもseleniumの情報を検索すると、こうした表記が見られます。Byを使ったものに読み替えれば問題ないようです。
findメソッドを繰り返し使って要素を絞り込む
find_element、find_elementsは繰り返し使って絞り込んでいくことができます。
以下のようにまず親要素を取得して、その中にある子要素を取得できます。
# <div class="parent">
# <p class="child"> のような場合
parent = browser.find_element(By.CLASS_NAME,'parent')
child = parent.find_element(By.CLASS_NAME,'child')要素からテキストなどの情報を取り出す
見つけた要素のテキストは、.textというプロパティで参照できます。
#find_element
name_element = browser.find_element(By.ID,'name')
name_text = name_element.text
#一行でも書ける
name_text = browser.find_element(By.ID,'name').text
#find_elements(複数)
name_elements = browser.find_elements(By.CLASS_NAME,'name')
print(name_elements[0].text)
#すべてを出力
for elem in name_elements:
print(elem.text)
テキスト以外にもタグ名や属性値などが取れます。主なものだけ挙げておきます。
.text
.tag_name
.value_of_css_property("プロパティ名")
.get_attribute("属性名")ボタンやリンクをクリックする
複数ページにわたる情報を集めるときには、ボタンやリンクをクリックして次のページに移る必要があります。
要素のクリックは.click() メソッドで行えます。
# nextクラスのボタンを探してクリック
browser.find_elements(By.CLASS_NAME,'next')[0].click()終了する
browser.quit()基本的なところはこんな感じです。
取得したいデータの種類やサイトの構造に合わせたやり方はまた別に書きたいと思いますq